RECOMMENDED NEWS

COMPUTING
‘You are ChatGPT’: Leaked system prompt reveals the inner workings of GPT-5
What’s happened? A supposed GPT-5 system prompt leaked via Reddit and GitHub this weekend. The pro...
Read More →
COMPUTING
Having used the OnePlus 13s, this is what Apple needs to pay attention to
The idea of a truly helpful digital assistant has caught more steam ever since products like ChatGPT...
Read More →

COMPUTING
Kagi’s AI search assistant gives you access to all the big models in one place
Kagi’s “Assistant” feature, previously only available to Ultimate subscribers, is now rolling ...
Read More →
COMPUTING
3 open source AI apps you can use to replace your ChatGPT subscription
The next leg of the AI race is on, and has expanded beyond the usual players, such as OpenAI, Google...
Read More →
COMPUTING
PlayStation is testing AI-driven characters, and I’m not a fan
If you’ve been dreaming about having a more in-depth conversation with one of your favorite gaming...
Read More →
COMPUTING
Apple Intelligence could solve my coding struggles — but this key feature is nowhere to be seen
About a year ago, I started learning how to code in Swift, Apple’s app development language. The i...
Read More →
COMPUTING
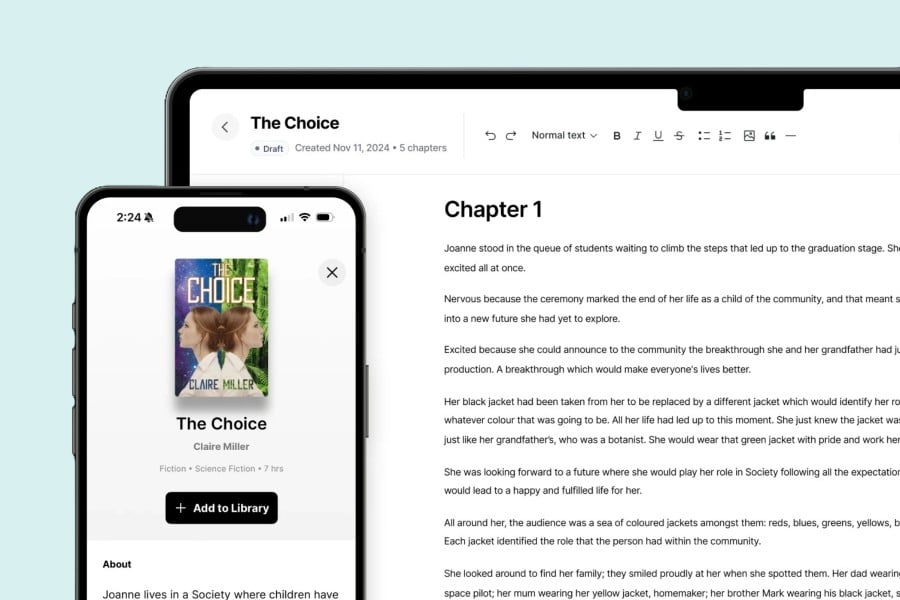
ElevenLabs AI will create audiobooks for you at no cost within minutes
ElevenLabs, the buzzy New York-based company specializing in AI audio tools, is diving headfirst int...
Read More →
Comments on "WeTransfer backlash highlights need for smarter AI practices" :