Midjourney’s new image generation model announced to take on OpenAI’s GPT-4o
Even though MidJourney set out to be one of the most promising image generation models in the early days of AI, it appears to have fallen behind more accessible, easy to use, and free tools such Gemini, ChatGPT, and Bing. Adding to its woes is the latest update to OpenAI’s GPT-4o model which allows exceptionally good image generation with the ability to recreate real photos and produce immaculate text. So to stay relevant — or perhaps catch the hype train being shunted by the wave of Studio Ghibli-inspired AI art flooding the internet, MidJourney is rolling out an updated model with several improvements.
CEO David Holz announced details of the new V7 model on MidJourney’s official Discord server and through a blog post. They said the new model is “smarter with text prompts” and produces images with “noticeably higher” quality and “beautiful textures.”
The model is also capable of generating images in a jiffy, roughly 10 times as fast as the current model, Holz says, as the mode is designed for brainstorming and frequent iterations. You can switch to the Conversational mode (only on web) and recreate part of the image without having to rewrite the prompt entirely or using the Edit mode. The images are of lower quality and cost half of what regular images do.
The Conversational mode is substituted by a Voice mode when you use the Discord app on your computer or mobile. Holz says it enables you to “think out loud and let the images flow beneath you like liquid dreams.” This feature is also part of the newly introduced Draft mode.
Additionally, MidJourney V7 can be run in Relax and Turbo modes for high-resolution images (than Draft mode), and using the latter will cost you twice as many credits in exchange for faster image production.
The new V7 model currently lacks some functionality and workflows will default back to the previous V6.1 for tasks that need upscaling, inpainting, and retexturing. Finally, the model also enables Personalization where you can save preferences on how you like your images and expect the model to produce results accordingly. This would require a five-minute setup, which takes you through a series of 200 images that you can choose to tune your preference.
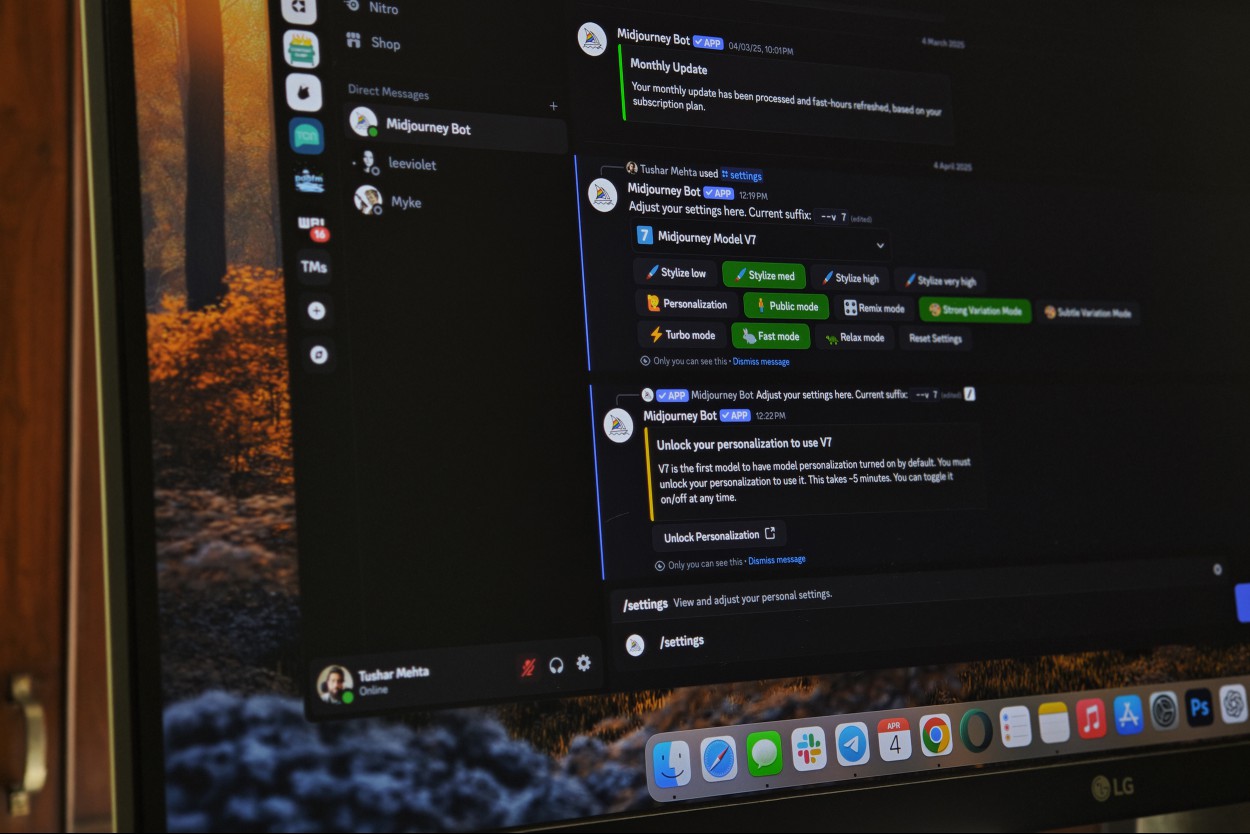
MidJourney is currently running a community-driven alpha test for the model, and promises additional features in the next 60 days. You can try it by typing /settings in the chat box in Discord or the web platform, send the message, and change the default model to V7 from the settings that emerge.




Comments on "Midjourney’s new image generation model announced to take on OpenAI’s GPT-4o" :